|
||||
|
CONTENTS 1. Project description |
||||
1. Project descriptionSoviet literature does not merely consist of authors from the school curriculum, members of the Writers’ Union and winners of state prizes. Many books published during the Soviet years are now almost forgotten — and yet they shaped the literary landscape of the era. Our project will allow modern readers and researchers to get acquainted with this «great unread». Our project dataset and research are based on the recognized texts from the Letopisi Digital Archive (http://letopisi.dlibrary.org) which includes Knizhnaia letopis’ - the largest Russian bibliographic index published weekly since 1917. It records more than 6.5 million editions published in the Russian Empire, RSFSR, USSR and Russia. From the entire array of data on the book market, we decided to focus on fiction and children’s literature. There are few research works dedicated to data derived from Knizhnaia letopis’; furthermore, not many scholars know about the existence of the Letopisi Digital Archive. Working with this unique electronic source and drawing attention to a scarcely known online collection which can be useful for students, scholars, professors and librarians seems to be a meaningful task to us. At this stage of the project we plan to research the data on literature published during the early Stalinist era between 1929 and 1940. Such a scope will allow, firstly, to carry out a study within one period of Soviet literature, and, secondly, to refine the methodology for processing and systematizing the bibliographic records contained in Knizhnaia letopis’ that could be applicable to other historical periods. 2. Work stages and methodsThe first stage will be the processing of several hundred issues of the Knizhnaia letopis’ for the years 1929-1940. We will collect data based on the following criteria: author name and gender, book title, year and place of publication, publisher, circulation, text specificity (poetry/prose). To extract metadata, we will use a Python parser. We will prepare a table database that includes all metadata for the specified period. We will use a specialized TEI markup language to extract information about authors’ names. Then we will check the extracted data against the text of Knizhnaya letopis’ to avoid inaccuracies. This database is a convenient way to work with the collections, because the OCR format (recognized text in pdf) is not suitable for full-fledged copying and searching. The next stage will be the visualization of the materials. Our team has developed several plots around which the infographics will be built. Among them: creating an interactive map of Soviet literature; infographics of the most circulated editions (general “top books” and statistics by republics during a selected time period); graphs illustrating interesting intersections of writers in different publishers. First and foremost is the GeoJSON tagged map, which will show where and how the most writers were published during the Soviet era and how this has changed over time. In addition, interactive charts using Plotly, statistical graphs, and two-dimensional data visualizations using Matplotlib and Seaborn will be developed. They will help visualize the gender, age, and other characteristics of writers and their publication activity. To demonstrate the interaction of authors in different publications, we will make a network analysis with the program Gephi, which will also help us to visualize the data briefly stated in the bibliography. All infographics will be placed on the project website (https://sovlitmap.ru). Explanatory texts and an introductory article about our project and the resource Knizhnaia letopis’ will complement the visual component. At the end of the project we plan (1) to present a new online resource containing an eye-catching visualization of the derived data in the form of an interactive infographic map of the Soviet Union, 2) to conduct a workshop/conference for the Soviet literature researchers. 3. What can we learn about Soviet books from the «Map of Soviet Literature» project?In the corpus analysis we plan to identify the most interesting trends in the works of fiction published between 1929 and 1940. One of our preliminary ideas is to study the typology of titles according to the method of “long distance reading”, which was developed in the works of Franco Moretti. In the course of the project we will do research for a scholarly article. After its publication, we will also open a special section on our website, where we will upload voluminous tables of collected data - these materials will be of interest to researchers of the Soviet epoch. Convenient systematization of these works and related data will facilitate new studies in this realm. Our «map» not only reflects the geography of Soviet book publishing, which was concentrated in Moscow and Leningrad, but also recreates the structure of connections between authors and publishing houses, the dynamics of circulation and prices of Soviet books, the gender ratio of writers, genre affiliation of publications, and much more. 4. Preliminary results for year 19294.1. Parcing OCRed text from Letopisi Digital Archive - Step 1
4.2. Parcing OCRed text - Step 2
4.3. Parcing OCRed text - Step 3
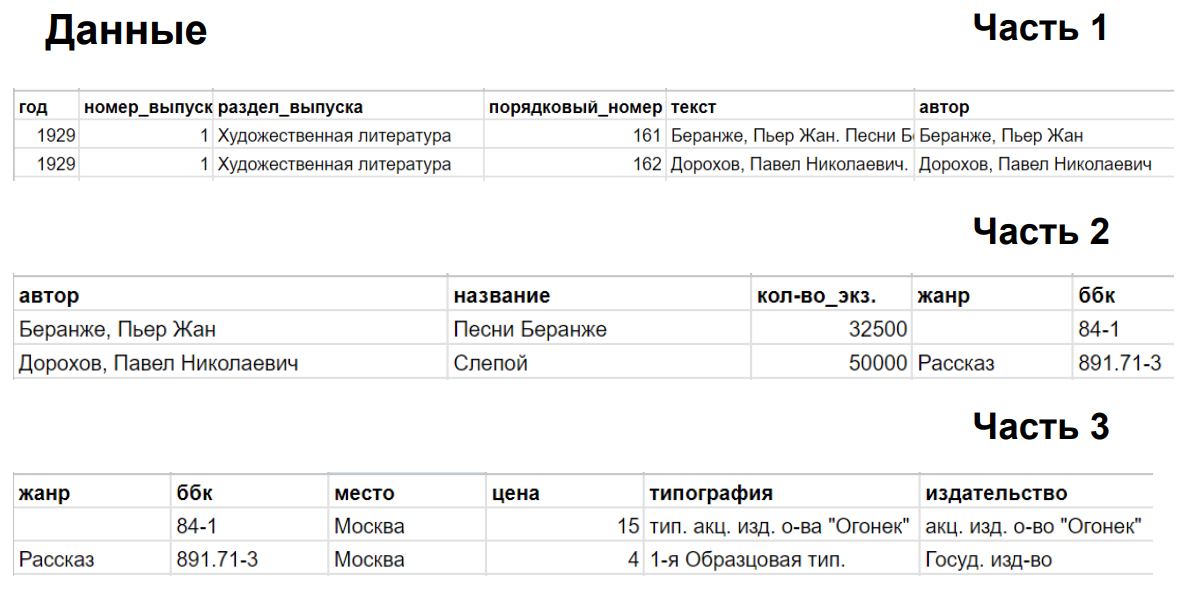
4.4. Converting parsed data to MongoDB
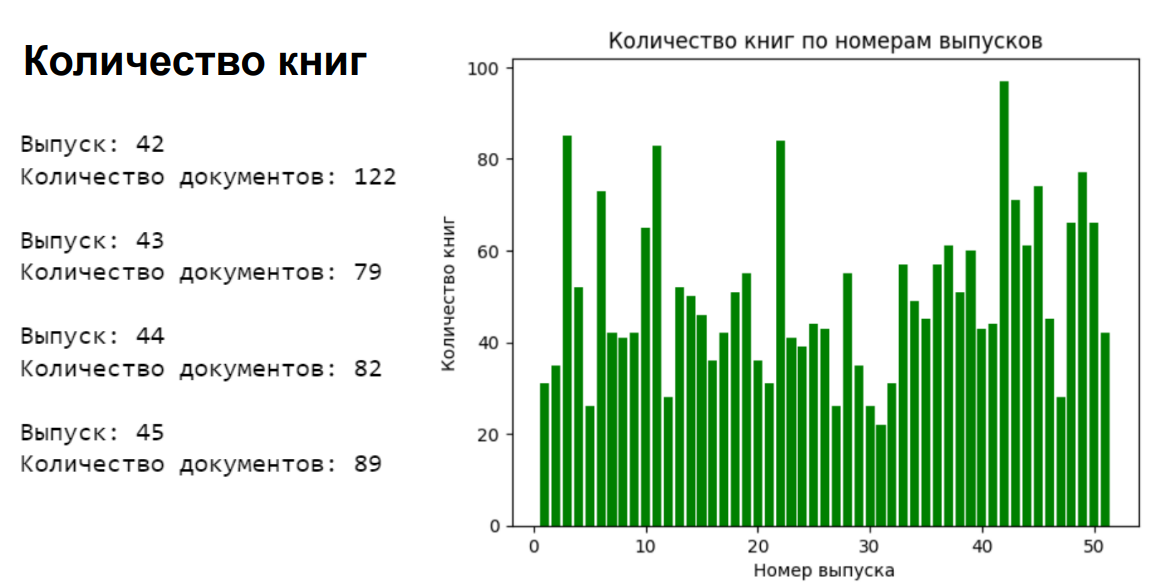
4.5. Visualizations - Number of fiction and children books by issue
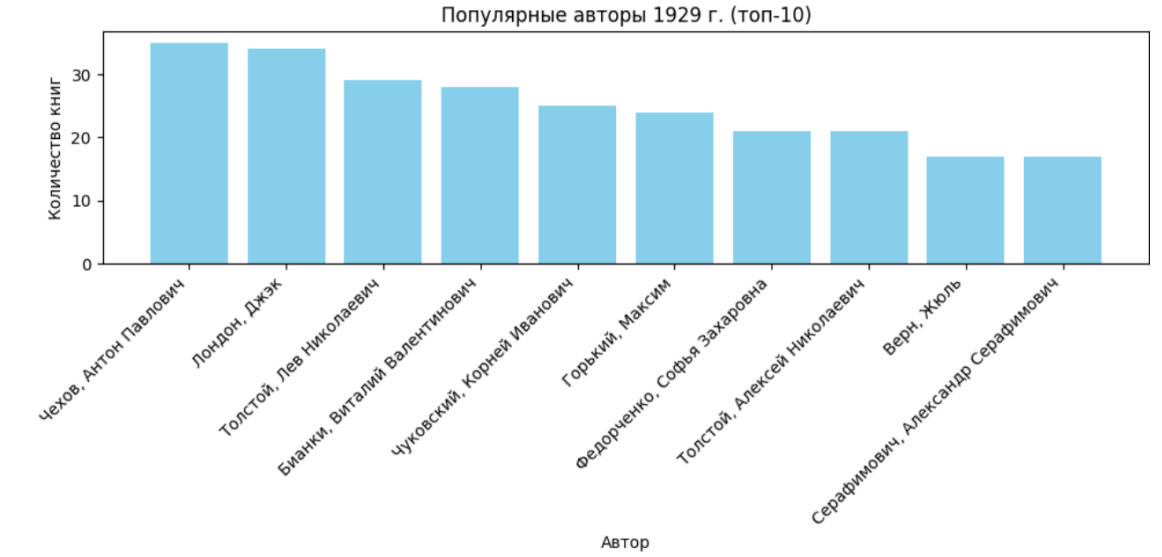
4.6. Most popular authors by number of books
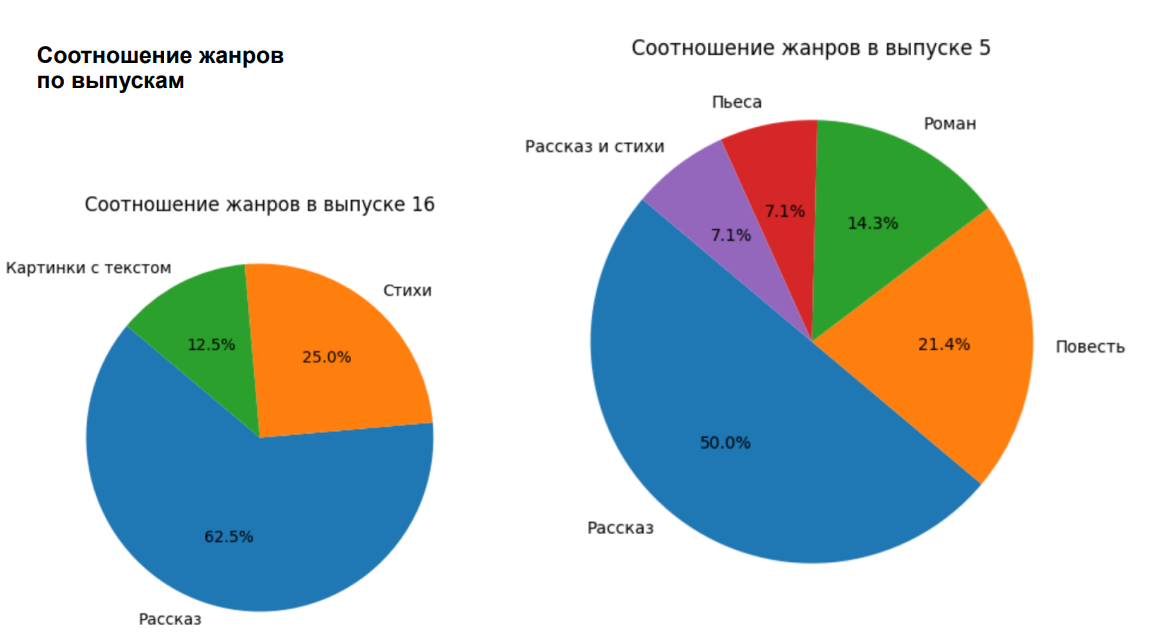
4.7. Literature genres
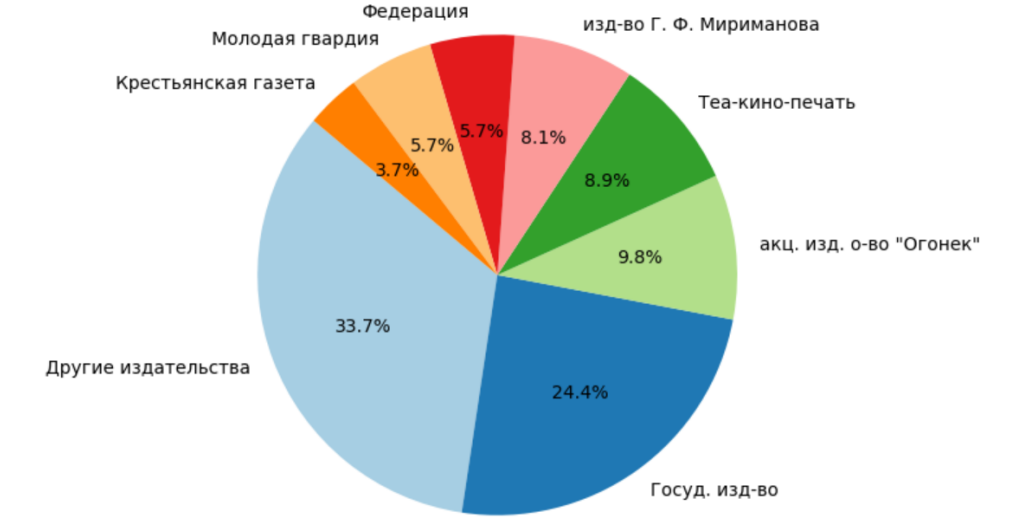
4.8. Moscow publishers
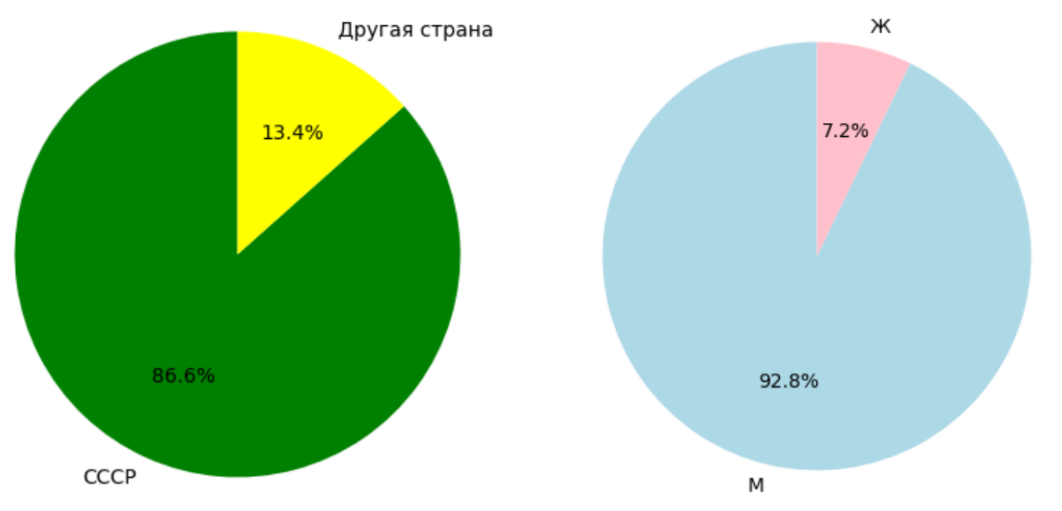
4.9. Writers by country and gender
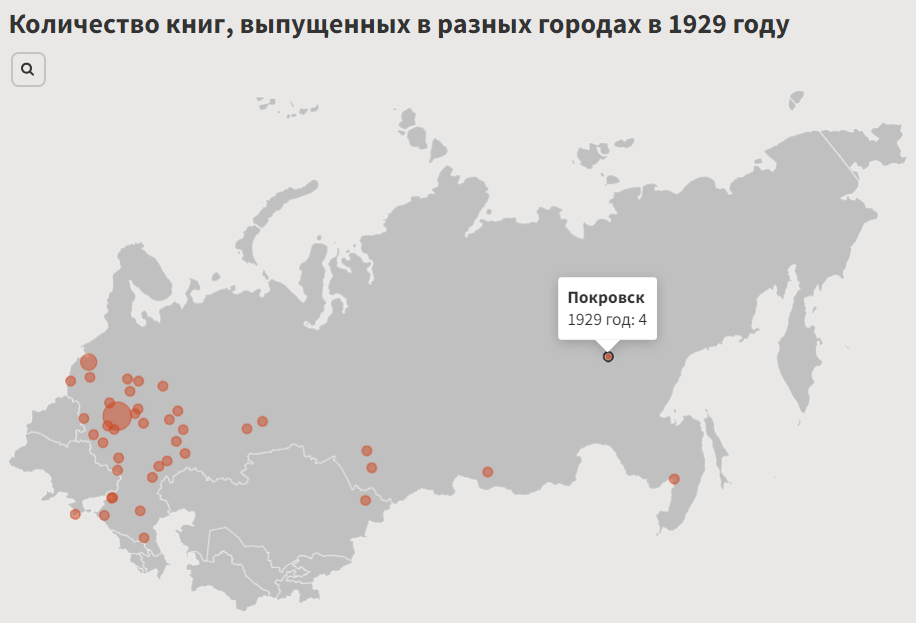
4.10. Number of books by city of publication
See more visualizations at https://sovlitmap.ru/датасет/ 5. Who we are and how to contact usWe are a group of master’s students from the Faculty of Humanities of the National Research University Higher School of Economics. We are interested in Soviet literature and big data. Our team was formed thanks to the HSE Academic Fund programme. You can learn more about us in the «Team» section. Please share with us your ideas, tell us about similar projects and join the team (sovlitmap@yandex.by). We look forward to your emails!
|